Uniting the digital and visual world With Context
- Foreword into Augmented Reality (AR)
- What do the brain’s biological limitations tell us?
- What can we learn from the Army?
- How will AR powered With Context be more delightful to us than smartphones?
- Existing participants that lower the barrier
- Development Plan
- Further business opportunities
- Summary
Foreword into Augmented Reality (AR)
There are two equally rich worlds. The real world we move through (the visual world), and the digital world of the internet, books, data servers, and LLM’s that live stationary at fixed entry points such as laptops, phones, and increasingly on audio interface touch points.
Our brains are not designed to unite the vast visual world with the equally vast digital world. As a consequence of this fact, I believe that AR embedded with AI empowered assisted decision support software systems that bridge these two worlds represents the same gain of function for society to the extent ChatGPT empowered humanity to conquer the digital world.
What do the brain’s biological limitations tell us?
From the retinal photoreceptors to our occipital lobes, a daisy-chain of hierarchically organized neurons of many kinds achieve 1000:1 compression of our visual world into concise information that can be reasoned with by our brains in real time. The net effect of this is that you never think about 99.9% of what your eyes see because an entire visual executive “assistive” repertoire is “handling it” before the rest of your brain needs to care about it.
Reading can, by comparison, feel efficient when content is compressed. Yet, it becomes inefficient as character count you read grows in size. This is because text is symbolic and linear. Yes, syntactically, language is compressed, but requires sequential decoding to make sense of it even when focused solely on reading. This fundamental difference becomes even more clear when what you read earlier has to be paired with live visual input you’re seeing now.
Why do we suck at this task? It’s our biology and an evolutionary legacy! Separate neural subsystems are engaged between text (Broca’s, Wernike’s areas) and vision (V1-V4, IT). These systems are operating in parallel. Integration between these two neural subsystems only happens in higher order neural structures such as your prefrontal cortex and that structure is slow and capacity limited. There’s also little pre-computation of text compared to visual information. The hierarchy of daisy-chained visual neurons enables pre-compilation of visual information. There is no such hierarchy for language based information. From a biological standpoint it justifies why tools like GPT that summarize, diagram etc., have taken off in such a dramatic way: these models offload and “assist” the job that your pre-frontal cortex used to spend manual cycles on onto a external digital-organ that pre-processes this for you.
You’ve probably unknowingly got an intuition of how humanity has mitigated for our evolutionary bottleneck and why it gives us delight when pre-computation of the visual and digital world is done for you (and makes others money). If you’ve looked at an ad or just about any marketing you’ll know that great marketing is a combination of highly compressed text and visual cues that’s insightful, actionable, and persuasive. Someone has done the visual and textual pre-computation to make the process of making (or swaying) a decision for you trivially easy.
Anywhere money is made through rapid perception and low-effort cognition you will find systems that pre-compute visual-text mappings.
First, computer vision models parallelized visual computation to beyond the parallelization limit of human abilities. Then, LLM’s became the de-facto extra-corporeal organ for textual pre-computation. What’s next? I think its application of AI that uses multi-modal input prompts that is then in turn used to unlock and gather from the vast digital world by commanding networks of AI agents. Returned information has to be thoughtfully compressed using AI at the interface that people would derive the most delight from being able to act upon this information.
Finding the right visual cues to unlock the right access of the relevant digital information in a way thats thoughtful and actionable is the core concept of a decision intelligence SDK and tooling layer that I want to build for the world.
What can we learn from the Army?
Thank you to our military-service members
I spent months working intensively on projects with AFC (now TRADOC) when I was at Actuate and that culminated in a test of my work in a life-fire exercise on a base (poorly pictured below - lets just say an M109A7 firing down range will scare the shit out of you). I might look like a total dork here but it was honestly one of the most humbling and informative learning experiences of my life. I am truly humbled by our service-members. Without this there would be no concept of “With Context”.

Using well designed decision support AR systems
The U.S. Army and other military branches have decades of R&D into heads-up-display (HUD) systems. You’ve probably seen them mounted on guns, mounted on pilots and lately in autonomous tracking. There are many design philosophies in cognitive ergonomics, information compression, and perceptual prioritization that help enforce I perceive how humans should experience AI that’s embedded in decision support interfaces such as AR glasses.
1. Cognitive bandwidth is a UX constraint
Too much data ≠ better decisions
ChatGPT can’t help but spit out just gobs of text. Its insanity. The training runs responsible for aligned AI systems contribute to this problem. So much effort is put into libraries that constrain or structure these generations. The military has a clear doctrine on this:
2. Data relevance beats quality
Offer useful data, don’t offer useless data.
Intriguingly, early HUD’s were poorly adopted because they dumped raw telemetry (altitude, speed, bearing) at all times in all contexts. Ever sit on an airplane today? Yeah, what good is knowing the distance to your destination when you’re landed at your destination? Or even the ground speed? Pointless.
3. Intuitive symbols leverage your visual cortex
Sprites and emojis are your friends
Your mind is adapted to visual context and visual memory! Use it. Taking advantage of standardized symbols (think: Stop Sign, Warning, Road Closed) that are engrained in our visual memory is key to making the decisions actionable.
4. Make the AI output aligned with the visual scene
Use vLLM’s to obfuscate prompting/programming
One of the fastest ways to have HUD be unusable is to have them deliver context that isn’t relevant in that moment, that isn’t ephemeral and is high latency. These were impossible barriers to cross not more than 1 year ago as vLLM’s were still in their infancy. Fortunately, companies like Moondreamare tackling this problem head on. Tiny LLM’s are the rage now, Tiny vLLM’s are the next.
5. Leverage attention to be relevant but not annoying
Don’t be annoying
Ok this one isn’t from the military but brought up from a Bronx native - yes, Chris Hayes. In an interview with Hasan Minhaj he talks about his book about human attention. Specifically, there are two kinds of attention: voluntary, and compelled. We are subjected to compelled attention mechanisms (e.g. car is honking, should I respond? Phone is buzzing, should I respond?). In things like AR glasses we have to be mindful of the fact that the wearer likely has one other device in his pocket begging for his attention. The Apple Watch has done a better job of being less attention seeking and therefore more relevant (I think). Similarly for UX design we have to think carefully about how the interface is to wield your attention and then unwield it just as fast so as to prevent fatigue, feel ambient, and feel ephemeral. This ephemeral, context driven nature of the equation is also key for a business model here.
Summary
A friend and collaborator once told me that wearable AR tech for decision-making should feel like the difference between a good executive assistant (EA) and a bad one. I’ve never had an EA myself, but here’s how I imagine it. If you’re heading up an elevator to a big boardroom meeting, the good EA is prepping you on the way up. They’re making sure the critical context is top of mind right before you walk in. That’s how good military HUD systems work. A solid AR decision support system ensures you’re not just present, but prepared. It makes you capable in ways that go beyond what you could manage alone.
The hackathon where we built “EyyyyWear” was our way of pressure-testing this idea. It forced us to build AI agent overlays under real constraints. As developers, we felt those constraints in code. Delivering decision support while humans are in motion is not easy. But that’s where the value shows up. You check if a parking spot is open while your car is still moving. Why? So you can stay nimble in your car, avoid wasting time, and skip a parking ticket all while keeping your hands on the wheel.
The hackathon at Betaworks was just an example. The larger point is that these systems are most useful when they meet you in real time, in your flow, in-context. The word “context” really matters here because its a sharp break from the way smartphone apps were designed. Lets get into that next.
How will AR powered With Context be more delightful to us than smartphones?
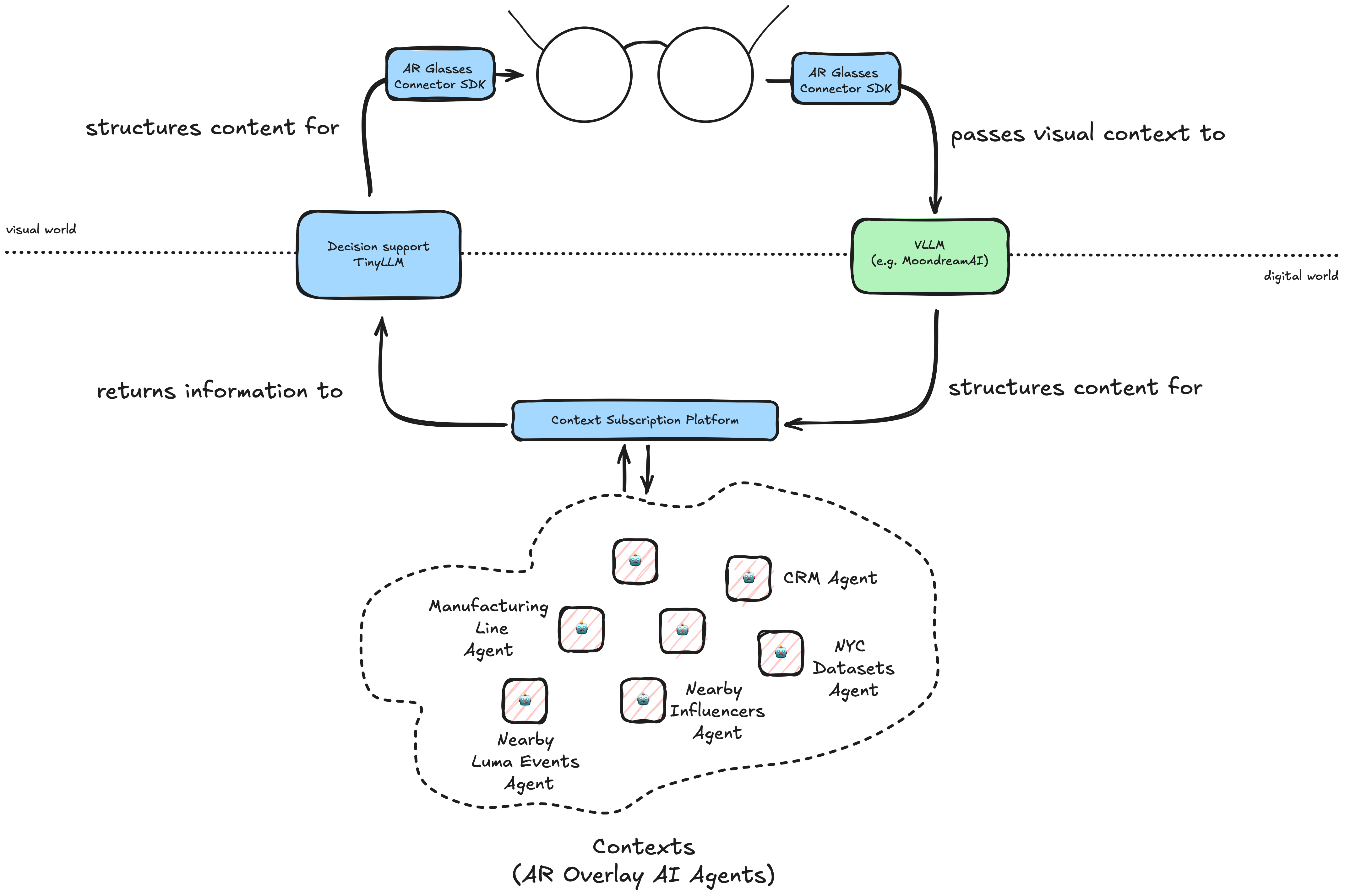
In the era of smartphones: users tap icons, add text, and scroll through apps bought on app stores. Your world is inside the app. In the wearable AR world, I believe that real world is your interface. What appears in your AR glasses while you’re in the real world is driven by the contexts you subscribe to. Contexts are overlaid AI agents that use images as sophisticated prompts to other models and leverage other AI agents to provision digital datasets to bring meaning to your visual world. I’d love to use this next section to make a case for the fundamental shift between apps and contexts.
They will provide Context, not “Experiences”
The smartphone app is an “intention-driven” interaction. You buy it, you touch its interface, you let the app decide, you share your experience on it with others. Whether you’re present in our earthly environment or not is beside the point when using an app. You’ve probably seen this when you’re with your friends and they go on their phones. When they’re on the app, they’re in the app. The app is running in their mental foreground, and the developers who created the app have curated the runtime “environment” to keep you engaged. Monetization in the app model is dependent on how much more of the app you want to lock into. Humanity has adapted, and subsequently become fatigued, to the concept and economics of the “app”.
In AR, because the visual world is the interface, we’ll be accessing different overlay AI agents that own and curate relevant context to your interface at that moment. I call them Contexts for short. They wont be something you touch, or intentionally download, they will function specific to visual context. You will be the decision engine, not the app. The net effect of this is: you won’t have to unravel structured visual understanding into low bitrate “words” with your brain, Contexts will see what you see and do what you normally would’ve done with your phone to aid your decision making. I believe this will be of higher use to society than apps ever were.
Monetization is ambient and quality reinforcing
With smartphone apps, you are paying money detach yourself from the visual world. You then pay even more money for more expensive applications that promise that with AI and AI agents, your time on the app and therefore the length of time you’re detached from the world will shorten.
I think the monetization strategy of “eyeball commitment” is one ripe to be flipped on its head. It goes without saying that desktop class applications like “Cluely” which bring decision intelligence as a service to the desktop have scratched a societal itch on this exact business model. To me, this provides validation that we’re touching a very real sore-spot that’s driven by our biology. Cluely’s business model, however, is still very SaaS centric ($20/month) because it lives atop other SaaS applications.
I believe we should monetize those AI’s that best function in the digital world where it “sees best”, and shepherd that returned information back to the physical one where we “see” best. Instead of paying to unlock an app, you pay to unlock the right “Contexts” for you.
| Apps | Contexts |
|---|---|
| App Purchase | No fee to download the “Context Platform” |
| App Store fees | Usage fee for different Contexts |
| In-app purchases | Higher usage fee for more involved, deeper knowledge parsing or more computationally complex AI agents that require longer reasoning |
Deliver actionable insight, not just delight
Most apps don’t leave you with an “actionable” insight, despite leaving you delighted by the UX, UI or a combination of the two. Owing to the constrained interfaces of a heads up display on a pair of glasses, outputs need to be short, punchy, and to the point. Designing for this constraint has to exist at the core cultural level of any “Context” creator. With Context will provide the MCP adaptors, tooling, and even other models in the loop to ensure that the user experience is actionable and purposeful.
Existing participants that lower the barrier
Software Infrastructure
Every AR device manufacturer has some form of a developer SDK that enables device level control of the hardware. Mentra OS is no exception here, providing abstraction over multiple devices to enable developers to readily create applications for a suite of AR glasses.
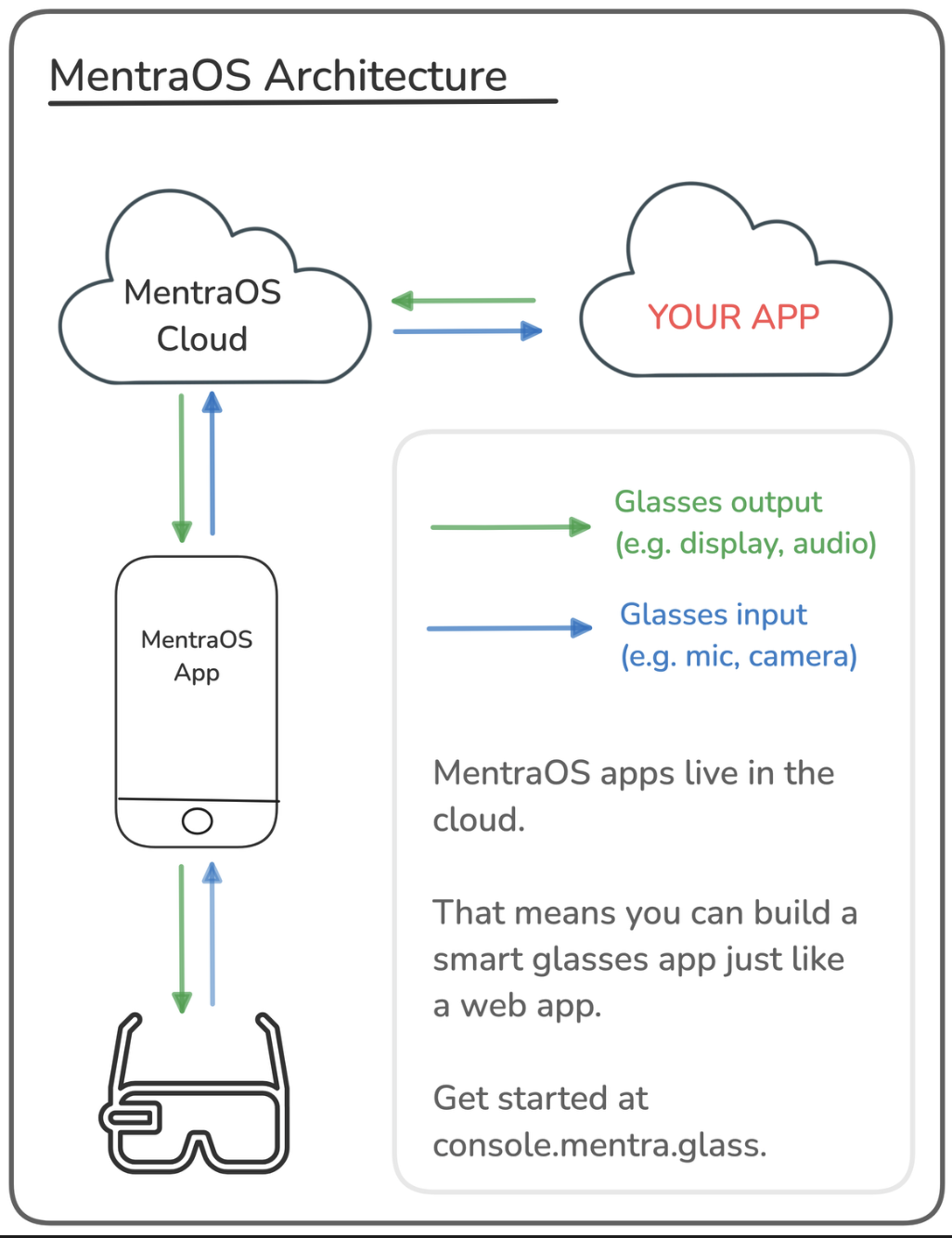
Note about Mentra
MentraOS and Mentra Merge are upcoming products alongside Mentra’s glasses. They are also cognizant about AI agents and I believe are well suited to produce the sort of AI overlay context agents I am talking about.
vLLM models
There are an increasing number of vLLM makers, most notably Moondream.aiwho are uniquely solving both minification of vLLM’s and also increasing model throughput and inference speed. These represent important bridges between the visual and digital world.
Digital AI agent makers
It goes without saying that this venture cannot exist without an ever growing army of AI agents and MCP servers making their way into production grade applications. Even just 1 year ago when some of these AR devices were manufactured and sold for the first time, the concept of AI agents did not exist. Deeper and potentially interesting enterprise grade integrations using digital AI agents will fuel interesting use cases for AR “Contexts”.
Development Plan
| Level | Focus | Description |
|---|---|---|
| 1 | Validate a Device SDK | Despite the fact that there are hardware SDK providers, not all devices are on the same SDK framework (e.g. Typescript). Fortunately most do have the underlying primitives and open documentation to get started. |
| 2 | Prototype/Sell manually designed use case | We previously demo’ed EyyyWear for a parking use case, and have eyes on other more monetizable use cases in sales and potentially sports applications to gauge business interest. We will leverage existing tooling and platform where possible to deploy quickly. |
| 3 | Survey the landscape of AI Agents suitable for Context Platform | Qualify sustained interest and pitch if other contexts (overlay AI agents) would be useful in a decision intelligence setting. |
| 4 | Design Context Subscription Platform | If sustained interest is yielded then we will move into designing a context subscription platform “app” that will serve as the “app platform” or “store” for multiple contexts. |
| 5 | Create adaptors for existing MCP’s or SDK for AI agents (or create new MCP’s) | Some business interesting AI agents might not be suitable for decision intelligence, they will need to be modified or adapted to functionally return actionable insights or intelligence. |
| 6 | Automate decision intelligence with novel AI models and evaluate existing vLLM models | We will need to better prompt or fine-tune an AI to tailor responses to be actionable for decision support given diverse outputs from multiple Contexts and multiple visual world inputs. |
| 8 | Evaluate AR hardware performance for future use cases | We may need to progress to developing our own hardware to better suit AI / AR needs. |
Further business opportunities
Here are some example uses that one could use With Context’s Context agents in:
| Trigger | Overlay Response | Context Agent Complexity |
|---|---|---|
| 👀 Look at a restaurant | Show Yelp score, menu, wait time | Low |
| 🤲 Hold a prescription bottle | Show dosage instructions, and number of refills available. | Low |
| 🔧 Face HVAC equipment | Show when the next filter change ought to happen. | Medium |
| 📸 Gaze at a person at a sales event | Show lead history, next action, notes. | High |
There really are a number of use-cases that could also be worked on with branded partnerships such as those with sports leagues for entertainment or enhanced insights for fans who would appreciate that level of engagement.
Summary
Augmented reality (AR) and artificial intelligence (AI) together offer a powerful method to bridge the visual and digital worlds, addressing our human cognitive limit. Our brains naturally separate visual and textual information into different processing pathways, leading to inefficiencies when integrating both simultaneously. A fundamental shift in monetization from traditional app-driven models to context-driven overlays can enhance user experience significantly. Fortunately, the existing ecosystem already includes robust infrastructure such as device SDKs, streamlined visual-language models (vLLMs), and advanced digital AI agents, providing a solid foundation for developing Contexts. If actionable intelligence With Context sounds interesting to you, reach out to me! I am building in this space.